
خوشه بندی با ترکیب الگوریتم k-means و الگوریتم ژنتیک
خوشه بندی با ترکیب الگوریتم k-means و الگوریتم ژنتیک ، عنوان پروژه ای می باشد که در این ساعت از مطلب دی ال برای دانلود قرار داده ایم.در ادامه توضیحات پروژه و لینک دانلود این پروژه آورده شده است.
خوشه بندی با استفاده از ترکیب الگوریتم خوشه بندی k-means و الگوریتم ژنتیک
در پروژه خوشه بندی با ترکیب الگوریتم k-means و الگوریتم ژنتیک بر اساس خواسته پروژه (در ادامه جزئیات کامل آورده شده است) ، از ترکیب خوشه بند k-means و الگوریتم ژنتیک برای خوشه بندی دادهها استفاده شده است. روند کلی بدین صورت بوده است که ابتدا با الگوریتم k-means مرکز خوشهها معین شده اند ، سپس از این مراکز به عنوان بخشی از جواب اولیه الگوریتم ژنتیک استفاده شده است. در انتها با اجرای الگوریتم ژنتیک مراکز خوشهها با معیار کم کردن فاصله درون خوشهای بروز رسانی شده اند.
خواسته ها یا مراحل پروژه خوشه بندی
۱- پیاده سازی الگوریتم ژنتیک
۲- پیاده سازی الگوریتم خوشه بندی k-means
۳- ابتدا داده ها را به الگوریتم k-means داده ایم و با این الگوریتم مرکز خوشهها معین شده اند ، سپس از این مراکز به عنوان بخشی از جواب اولیه الگوریتم GA استفاده شده است.(خروجی الگوریتم k-means را به الگوریتم ژنتیک داده ایم)
۴- ترکیب مراحل ۱ و ۲ ( سه بار الگوریتم k-means که خروجی این را به ورودی الگوریتم ژنتیک می دهیم و یک بار هم الگوریتم ژنتیک )
۵- مرحله ۴ یعنی ترکیب سه بار و یک بار در مجموع ۱۰ بار اجرا میشود.
۶- فاصله درون خوشه ای = FITNESS FUNCTION
۷- شرط خاتمه evaluation =50000 باشد ( به این شرط که رسیدیم exit میکنیم)
جمعیت اولیه : n=30 در ژنتیک
C=20 crossover
m=15 mutation
هر بار که الگوریتم k-means اجرا میشود یک success rate به دست می آوریم ، success rate برای این می باشد که متوجه شویم داده های کلاستر شده درست کلاستر شده اند یا خیر.
الگوریتم k-means
این الگوریتم یکی از الگوریتم های کلاسترینگ داده ها در مسائل داده کاوی می باشد این الگوریتم برخلاف سادگی آن یک الگوریتم پایه برای بسیاری از الگوریتم های خوشه بندی دیگر (مانند خوشه بندی فازی) به حساب می آید.برای این الگوریتم شکل های مختلفی گفته شده است. ولی همه آنها دارای روالی تکراری می باشند.
گام نخست) در ابتدا K نقطه تصادفی به عنوان نقاط مراکز خوشه ها انتخاب می شود.
- K : مبین تعداد خوشه هایی می باشد که می خواهیم بسازیم
- مرکز خوشه ( mean ) : از حیث معنی میانگین موقعیت تمام نقاط در خوشه ی مورد نظر می باشد.
گام دوم) هر نمونه ی داده ، به خوش هایی که مرکز آن خوشه کمترین فاصله (بیشترین شباهت) تا آن داده را داراست، نسبت داده می شود.
گام سوم) با بدست آوردن میانگین داده های موجود در هر خوشه، مرکز جدیدی برای هر خوشه بدست می آید.
گام چهارم) گام های دوم وسوم تا زمانی که دیگر هیچ تغییری در مراکز خوشه ها حاصل یا برآیند نشود، تکرار می شوند.
تابع هدف در الگوریتم k-means
در الگوریتم k-means تابع زیر به عنوان تابع هدف مورد توجه می باشد. به عبارتی هدف کمینه کردن این تابع می باشد. هر چه مقدار نهایی این تابع کمتر باشد، یعنی کلاسترینگ صورت گرفته بهتر است.
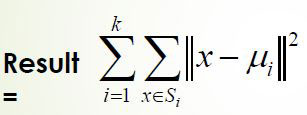
ویژگی های الگوریتم خوشه بندی k-means
- ایده اصلی در الگوریتم خوشه بندی k-means پیدا کردن k مرکز برای هر خوشه می باشد.
- یک الگوریتم تکرار شونده ، مبتنی بر تقسیم داده هاست data-partitioning
- تعداد خوشه ها یا کلاسترها قبل از شروع الگوریتم انتخاب می گردد.
- مراکز cluster به صورت تصادفی انتخاب می شوند.
- مراکز خوشه ها ممکن است عضو داده های اولیه نباشند.
- Lloyd’s algorithm نیز نامیده می شود.
به منظور ارزیابی تشابه میان نمونه های یک کلاستر در الگوریتم خوشه بندی K-Means از معیارهای مختلفی استفاده می شود برخی از معیارها عبارتند از:
- فاصله اقلیدسی Euclidean Distance
- بلوک شهری City Block
- داده های باینری Haming
- Cosine
- Correllation
تصاویری از نتایج پروژه



کارشناسان وب سایت MATLABDL قادر به انجام پروژه در زمینه های مشابه (پروژه های داده کاوی و…) نیز می باشند.
قیمت پروژه : ۹۲۰۰۰ تومان
حجم : ۷۷۳ کیلوبایت
توضیحات : پیاده سازی در نرم افزار متلب انجام شده است.
کلمات کلیدی: خوشه بندی,الگوریتم های خوشه بندی,الگوریتم خوشه بندی k-means,پیاده سازی الگوریتم k-means با متلب,الگوریتم ژنتیک,خوشه بندی با الگوریتم ژنتیک
منبع : مطلب دی ال
رمز فایل : www.matlabdl.com



 با استفاده از الگوریتم ژنتیک (GA)")





دیدگاه خود را ثبت کنید
تمایل دارید در گفتگوها شرکت کنید؟در گفتگو ها شرکت کنید.